In the last part i outlined a more data oriented approach that increased memory density, and allowed for more efficient processing. In this part i am getting even more performance from our CPU by going Wide.
Multihreading
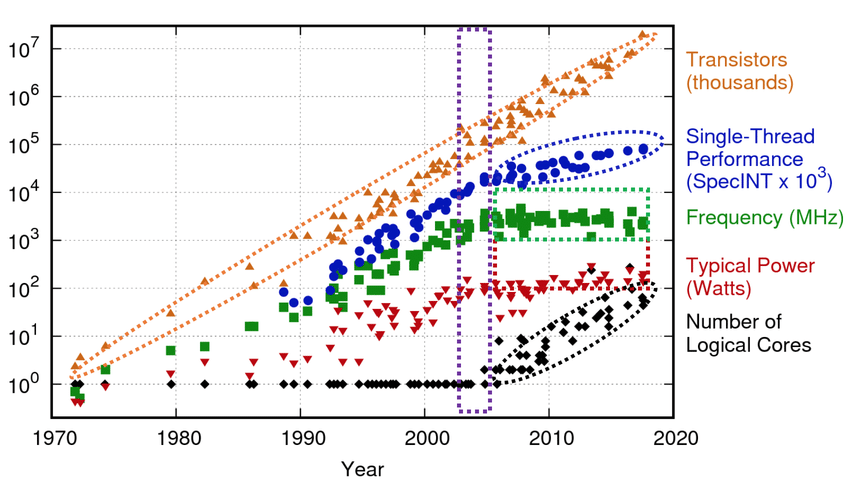
from algorithmica.org
Moore's law is the observation that the number of transistors in processors doubles about every two years. You can see that's the case from the blue data points in the graph above. Transistor count can be analogous to processor performance. However this is the total number of transistors. Since circa 2008 the single-threaded performance along with clock speeds have stagnated. The increase since can be mostly attributed to added logical cores. So far we have been running our code on a single thread, and therefore we do not get the performance benefits.
In the last post we layed out our data in such a way that easily allows multithreading. Particles systems are in the industry referred as an "embarrassingly parallel problem". This is because there are usually no shared data structures. (If however inter-particle interaction is needed, more advanced techniques are required). Instead of the particle system simulating each particle the number of particles are divided between threads for processing. This can easily be achieved with ThreadPools.
public class ParticleSystem : GameObject
{
// This is just a simple example. This example does not take into consideration:
// 1: that particles.length might not be divisible by ThreadPool.ThreadCount
// 2: that the system might not want to exit Update() before all the threads are done.
// 3: Doesn't use WaitCallback correctly
...
public override void Update()
{
int particlesPerThread = ThreadPool.ThreadCount/particles.Length;
for(int i = 0; i < threads; i++;){
ThreadPool.QueueUserWorkItem((obj) => { SimulateParticles(particlesPerThread*i,particlesPerThread*(i+1)); });
}
}
public void SimulateParticles(int start, int end)
{
for(int i = start; i < end; i++;){
lifetime += Time.DeltaTime;
particles[i].position += particles[i].velocity * Time.DeltaTime;
...
}
...
}
}
Vectorization
There is another way of going Wide. By using special instructions you can process multiple elements at a time on a single thread. Instructions like these are refered to as "Single instruction, multiple data" or SIMD for short. This method requires more forethought from the developer, since using them requires special memory and logic patterns.
When we're developing for desktop we're usually targeting the x86-64 / amd64 instruction set. It contains all the instructions that are available to us as developers. There additionally exists extensions that specific CPUs implement. These are also referred to as assembly intrinsics or simply intrinsics. They work by loading multiple values into a larger register, and performing the same operation on all of them simultaneously. This effectively increases throughput by the width of the operation. Let's look at adding two numbers together with SIMD instructions to get a better understanding of how to use them.
Adding two numbers with SIMD
__m128 _mm_add_ps (__m128 a, __m128 b)
(ref) is part of the SSE extension set. It takes two sets of four floats adds them together and returns another set of 4 floats. Instead of adding numbers one by one you can add four at a time! This can cause big speedups! In practice it's under 4X but still a lot. There is one practical caveat; being that the supplied variables have to packed. Let's try to refactor our code to use SIMD. Currently the implementation of the particle system looks like this:
public class ParticleSystem{
Particle[] particles; // <- Array of Structs
}
public struct Particle{
Vector3 position;
Vector3 velocity;
}
This way of storing data is referred to as an Array Of Structs (AOS). This in effect causes the memory be layout like this:
px py pz vx vy vz | px py pz vx vy vz | px py pz vx vy vz | px py pz vx vy vz
You can say that all fields are sorted by instance. Our goal is adding each Particles Velocity to its Position. However we cannot use the SIMD function since the we cannot supply it with two sets of contiguous variables. Instead we have to order the fields by variable meaning the memory layout has to look like this:
px px px px | py py py py | pz pz pz pz | vx vx vx vx | vy vy vy vy | vz vz vz vz
We can achieve this by storing our particle fields separately in arrays:
public class ParticleSystem{
Particles particles; // <--This is a Struct Of Arrays
}
public struct Particles{
float[] positionX;
float[] positionY;
float[] positionZ;
float[] velocityX;
float[] velocityY;
float[] velocityZ;
}
This layout is referred to as Struct Of Arrays (SOA). This now enables us to supply the function with a pointer to contiguous data:
px px px px
+ + + +
vx vx vx vx
↓ ↓ ↓ ↓
px px px px
This also only works if the number of particles is divisible by the width of the SIMD instruction, in this case 4. This can be solved by ensuring divisibility by ceiling the length or by using normal instructions for the last 1-3.
The SSE extension used above only supports a width of 128bits. Meaning we can only process 4x32bit floats at a time. Luckily we are not limited by SSE. Many additional extension sets and updates are constantly added. There's also AVX256 and AVX512 is right around the corner. There's a bunch of different functions not limited to simple addition or subtractions. The Intel® Intrinsic Guide is the best online reference for intrinsics. There you can also get a overview of the naming schemes.
Using Intrinsics in .Net
There a couple of different ways of explicitly taking advantage of SIMD instructions. By using the built in managed vector class in system.numerics, or the functions in system.runtime.intrinsics.
Here is an example from the source :
// Static function to add two arrays of floats together using SIMD
public static void Add(float[] a, float[] b, int startIndex, int endIndex)
{
if (Avx.IsSupported)
{
fixed (float* ptrA = a, ptrB = b)
{
for (int i = startIndex; i < endIndex; i += 8)
{
Avx.Store(&ptrA[i], Avx.Add(Avx.LoadVector256(&ptrA[i]), Avx.LoadVector256(&ptrB[i])));
}
}
}
else if (Sse.IsSupported)
{
fixed (float* ptrA = a, ptrB = b)
{
for (int i = startIndex; i < endIndex; i += 4)
{
Sse.Store(&ptrA[i], Sse.Add(Sse.LoadVector128(&ptrA[i]), Sse.LoadVector128(&ptrB[i])));
}
}
}
else if (AdvSimd.IsSupported)
{
fixed (float* ptrA = a, ptrB = b)
{
for (int i = startIndex; i < endIndex; i += 4)
{
AdvSimd.Store(&ptrA[i], AdvSimd.Add(AdvSimd.LoadVector128(&ptrA[i]), AdvSimd.LoadVector128(&ptrB[i])));
}
}
}
else
{
for (int i = startIndex; i < endIndex; i += 1)
{
a[i] += b[i];
}
}
}
Instead of the cryptic _mm_add_ps you can instead use the much more concise (System.Runtime.Intrinsics.X86.)Sse.Add().
If you know which device you're targeting you can directly use the highest width intrinsics available. When dealing with different CPU's I've found two solutions. If you're developing for a specific common range of hardware you can use the lowest common denominator to decide which intrinsics to implement. You should be able to support SSE3 and older since it got released in 2005 and is supported on all modern x86 hardware. The other option is runtime branching as you can see above. JIT compilation effectively removes the branch since it is a environment constant. This also allows for cross platform compatibility with for example arm intrinsics (AdvSimd). There is also an unvectorized fallback.

With these changes you can easily simulate way over 1.000.000 particles, you can see this in action on my Youtube Channel.
Source code
Thanks for reading this three-part blog post. Hoped you enjoyed following me this data oriented rabbit hole. I've personally learned a lot and hopefully you've also learned a thing or two. You can view the full source code over at GitHub. I do not recommend using the code in production but can serve as reference. In practice all modern Game Engines simulate their particles on the GPU and not CPU. If done on the GPU with compute shaders and indirect drawing, it will allow for even larger simulations.
In retrospect what I've inadvertently created an ECS system. The simulator is using separate data(component) and function(system) "modules". When I realized this I decided to change my focus on learning the implementation details for an ECS. The upcoming data oriented posts will be focusing on this.
If you have any questions you can tweet me at @sorensaket