In the last part I described the scenario I was in. when trying to implement a particle system with an Object Oriented mindset.
In this part I'm going in technical detail explaining why it is slow. First I'm going to quickly explain how a CPU cache works, to gain insight into what we can do to make it faster. Note that this explanation is simplified for the sake of understanding. If you want to learn more there are some further reading material in the bottom of the post.
Cache
The Central Processing Unit (CPU) is responsible for doing most of the operations in a computer. You have probably heard of the term GHz (Giga-hertz), it describes how many times a second the CPU can perform something. We refer to a single of these as a cycle. On average, you can think of the CPU as being able to do simple arithmetic in a single cycle. However to do computation, the CPU needs to access the instructions and data from main memory aka. RAM. This is extremely slow. Well that's not entirely true. It's the CPU that's fast.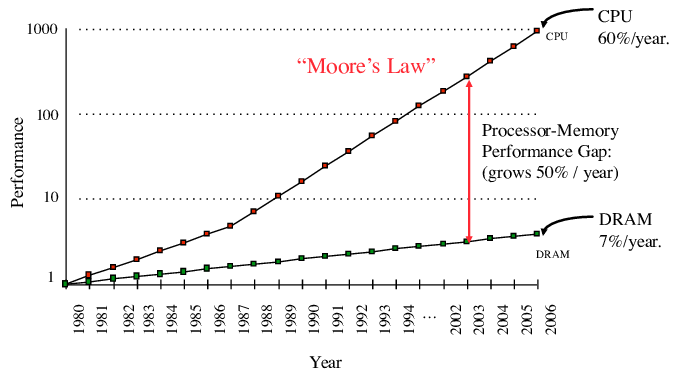
from algorithmica.org
Looking at the graph above you can see that CPUs have been exponentially becoming faster, whilst memory speed has been growing in a much slower pase. Notice how the Y-axis is in logarithmic scale. This is because of physical constraints. Because CPU computation is bound by memory access speeds, slow RAM can cause slowdowns in execution. An Add operation that would have taken just a single cycle can in reality take 150+ cycles when waiting for RAM. To combat the CPU just waiting for memory, cache was added to reduce necessary memory accesses. Cache is a smaller but much faster data storage physically closer to the processor. However the gap between processing power and ram speeds have been steadily growing. To compensate CPU manufactures have progressively added more cache.
Now we have multiple levels of Cache, usually 3. When the cpu can't find the required data in the L1 cache it will search the L2 then L3. If it fails it will go all the way to main memory. This is referred to as a cache miss. The CPU gathers an entire "Cache Line" at a time (usually 64 bytes). If another needed variable is within the same cache line it can just grab it from there. Also meaning if you need to asses memory elements sequentially they should be layed out that way in memory so they can be accessed from the same Cache Line.
Phew, that was a lot of knowledge at the same time. Here comes the practical part. How do we use this knowledge to increase the performance of our particle system?
TLDR:
To optimize cache usage:
- Reduce the memory footprint of your data, so that more elements can fit into a single Cache Line.
- Data storage order should match data access order.
Optimizing Data Structure
To utilize cache fully you need to reduce the size of your data and tightly pack it. Reducing the size of your data will directly lead to fewer incurred cache misses. Let's therefore analyze our current implementation to see how it can be improved.
Since each particle is a class (Reference Type) it will be stored randomly in memory on the heap. There is no guarantee that the particles are next to each other in memory. Especially because the objects are created at different times. Meaning our storage is not packed. This causes us to jump to a new address every particle causing non linear access and wasting cache lines. This also causes a bunch of other issues. The game used a single list to keep track of all GameObjects. Each particle was its own object in the GameObject list. Meaning all systems that iterate through the GameObjects also iterate each individual particles. Making the particle interweaved with other systems making everything slower!
The other problem was how big each particle was in memory. You can generally determine size by counting all fields in your type. How much a single field stores is a bit more tricky than it seems. How much memory a field uses can actually depend on which order they are stored. This is called Data Structure Alignment and you can read more about it on wikipedia. Generally in C# fields are automatically reordered to minimize padding, so lets ignore that fact for now. Additionally a boolean takes up a whole 1 byte/8 bits and a reference field is 8 bytes/64 bits on a 64 bit computer. Remember to do this recursively for all inherited classes. In practice it's more than this, since internally the CLR also stores additional information when storing a class.
Counting up this way the each particle roughly ended up taking up 190 bytes or 1520 bits. That is humongous. So how to we go about solving these problems? It's suprisingly simple when you've already learned the whys and hows. First of all, we can make each particle a struct and store them in a array instead. This ensures that there is no additional cost of using a class and that they're concurrent in memory. Secondly by moving all non instance state to a parent class. These are values like curves that determine behavior over time that are constant across multiple particles. Then the parent class is responsible for updating each of its particles. The solution will look something like this instead:
public class ParticleSystem : GameObject
{
public Particle[] particles;
public Texture2D texture;
// A bunch of curves controlling behavior over time
public Curve alphaOverLifetime;
...
public override void Update()
{
for(int i = 0; i < particles.length; i++;){
lifetime += Time.DeltaTime;
particles[i].position += particles[i].velocity * Time.DeltaTime;
...
}
...
}
...
}
struct Particle
{
public float lifetime;
public Vector3 position;
public Vector3 velocity;
...
}
Now each particle only takes 48 bytes or 384 bits. That means a density increase of 400%. In effect this will equally increase the data bandwidth. Data locality is also guaranteed since the particles are stored next to each other meaning that we'll get 1.25 particles per cache line. This was a proper speed increase! We went from simulating 20.000 particles to 100.000.
In this writeup i haven't covered more advanced concepts like Prefectching and Heaps. To learn more i would recommend these reading materials:
- Algorithmica is an open-access web book dedicated to the art and science of computing: https://en.algorithmica.org/hpc
- Wikipedia Cache prefetching
Click here to read part 3 where I implement Multithreading and Vectorization